Introduction
The project starts from a practical problem: keeping track of local prices with something more structured than manual browsing.
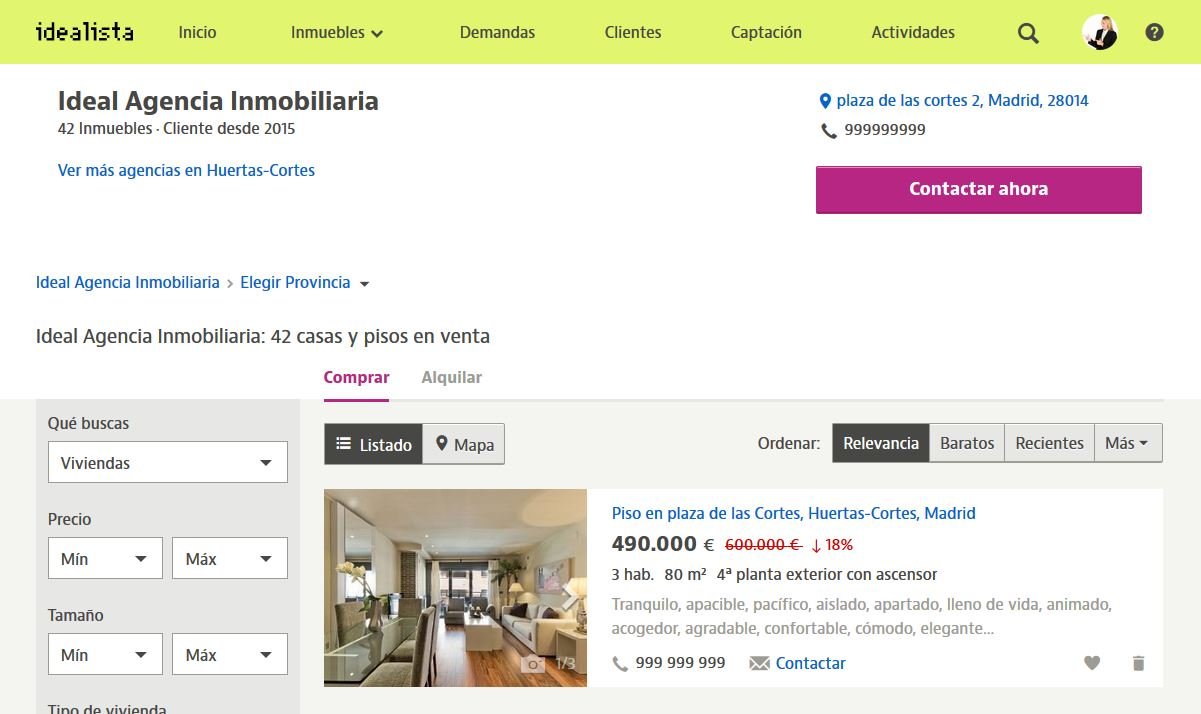
Idealista is a widely used real-estate portal in Spain and a natural place to start when monitoring market prices.
The project turns that recurring manual interest into a reproducible automation pipeline that collects listing data and feeds a simple baseline model.
Data collection
The dataset exists because the automation exists first.
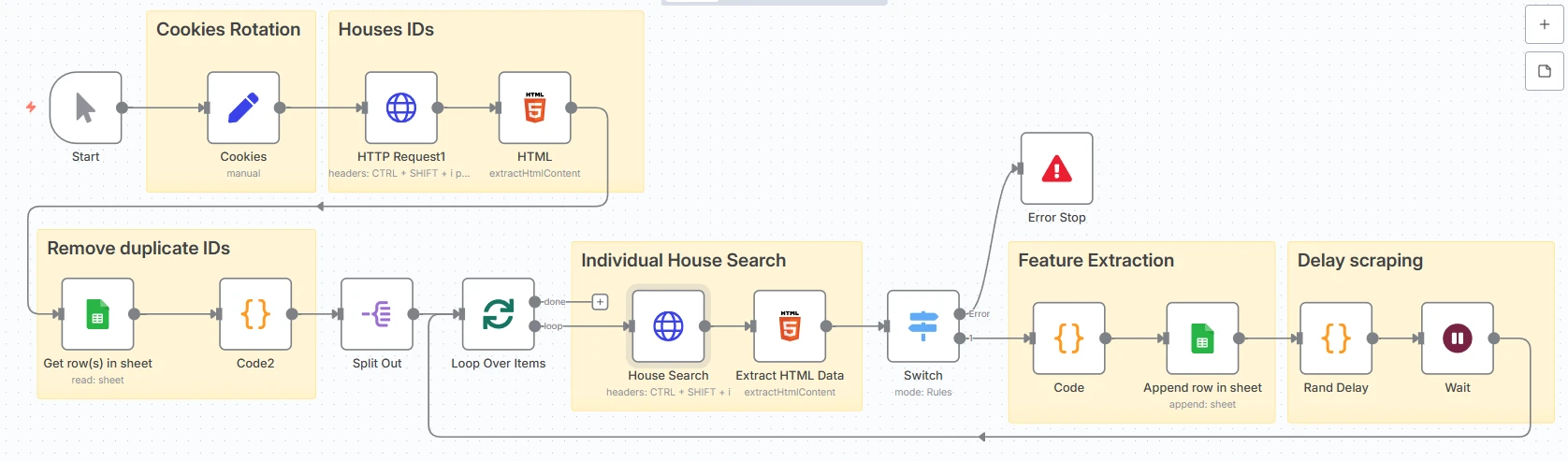
An n8n plus Python workflow periodically fetches new listings, deduplicates them, parses listing detail pages and stores normalized outputs in CSV or Excel formats.
The collection step matters as much as the model because the market has no clean ready-made dataset for a local niche area.
Analysis
With more than 500 homes collected, the dataset becomes useful enough for a first estimation model.
Feature extraction focuses on floor area, rooms, bathrooms, floor number, approximate location and textual hints that correlate with property condition.
The analysis is intentionally pragmatic: asking price is a noisy target, so feature quality and interpretability matter more than squeezing a flashy model into weak labels.
Model choice
- Use Linear Regression as the initial baseline because it is interpretable and appropriate for limited structured features.
- Treat the noisy target with caution: asking price is a seller decision, not a perfect ground-truth valuation.
- Keep room for richer models later only if the feature set becomes strong enough to justify them.
Issues encountered
- Property condition is often buried in unstructured text rather than exposed as a clean field.
- Listings frequently omit important values, forcing normalization, imputation and proxy features.
- Special cases like missing permits or poor renovation state create unavoidable label noise.
Results and conclusions
The observed error is roughly plus or minus 25k, which is sensible given the noisiness of asking prices and the amount of hidden information that cannot be inferred reliably from structured fields alone.
The real value of the project is the repeatable data pipeline and the ability to create a local, decision-support view of the market with a transparent baseline.
Next steps
- Analyze listing images to infer interior condition and renovation signals.
- Keep collecting data to enrich coverage across time and geography.
- Consider more robust or non-linear models once the feature quality justifies extra complexity.
Next move
Want the broader picture?
The rest of the portfolio pairs this kind of pragmatic automation work with machine-learning systems and longer technical write-ups.